Le ChatGPT est un outil développé par OpenAI dont le rôle principal est de produire des textes par le biais de l’intelligence artificielle. Il s’agit d’un système disponible dans plusieurs

Le ChatGPT est un outil développé par OpenAI dont le rôle principal est de produire des textes par le biais de l’intelligence artificielle. Il s’agit d’un système disponible dans plusieurs

2024 approche à grands pas, portant avec elle une vague d’innovations révolutionnaires en marketing digital B2B. De l’intégration poussée de l’intelligence artificielle à l’automatisation des parcours clients, chaque avancée offre

Que vous soyez un particulier soucieux de se protéger contre d’éventuelles escroqueries ou un professionnel ayant besoin d’identifier des clients ou des contacts, un site d’annuaire inversé peut être le

La qualité d’un gamer ne se résume pas seulement à ses propres qualités et à son niveau de jeu. Plusieurs sont les autres éléments qui concourent aux bonnes performances pendant

Si vous utilisez le site WordPress, vous avez sûrement déjà rencontré l’erreur redoutée : « Il y a eu une erreur critique sur ce site web ». Cette erreur peut être inquiétante

Il est clair que le monde de l’informatique est en constante évolution. À chaque instants, il se peut que de nouvelles tendances voient le jour, influençant les façons dont nous

Être en ligne aujourd’hui, c’est comme être dans une immense métropole. Il y a des sites web comme des boutiques, des blogs comme des cafés, des réseaux sociaux comme des

Le monde numérique est en constante évolution. Mais un élément reste constant : le besoin d’une stratégie de marketing efficace pour attirer plus de trafic organique vers votre site web.

Au sein de notre monde moderne, le niveau de bruit augmente constamment. Que vous soyez chez vous, au bureau ou dans les transports, vous êtes sans cesse confrontés à une

Dans un monde où le commerce électronique est roi, il est essentiel pour les entreprises de toutes tailles de comprendre comment créer une boutique en ligne performante et attractive. Que

En cette ère numérique, la présence de votre entreprise sur les réseaux sociaux n’est pas seulement souhaitable, elle est indispensable. Les plateformes sociales sont devenues une vitrine essentielle pour les

Vous êtes vous déjà retrouvé dans ce dilemme, face à un vaste choix d’écrans de jeux vidéo, et vous ne savez pas lequel choisir ? Vous n’êtes pas seul. Pour

Les rouleaux thermiques 57x40x12 et TPE sont des composants importants, mais souvent négligés, qui jouent un rôle vital dans le commerce moderne. Malgré leur invisibilité, ces rouleaux sont en fait

Faire appel à une agence PowerPoint offre de nombreux avantages à ceux qui souhaitent une présentation professionnelle et visuellement attrayante. Ces agences spécialisées possèdent une grande expérience dans la création

De nos jours, avec le rythme effréné de nos vies professionnelles, il est essentiel de chercher toutes les méthodes possibles pour augmenter notre productivité. L’un des facteurs les plus importants

La maintenance informatique est l’ensemble des différentes procédures à suivre pour résoudre les problèmes informatiques ou pour garantir le bon fonctionnement des équipements de travail comme les ordinateurs, les serveurs,

De plus en plus d’entreprises font aujourd’hui appel à des agences en ligne pour leur communication numérique. La communication numérique offre de nombreux avantages, notamment l’accès à l’expertise et à

Les chatbots de voyage sont devenus des compagnons de confiance pour les voyageurs du monde entier. Mais qu’est-ce qu’un chatbot de voyage ? Comment fonctionne-t-il ? Et surtout, est-il réellement

Imaginez-vous assis dans votre canapé, en train de planifier votre prochain voyage. Au lieu de parcourir d’innombrables sites web, de passer des heures au téléphone avec des agents de voyage

Dans notre société moderne, le sac à dos est devenu un accessoire incontournable, que ce soit pour aller à l’école, partir en randonnée ou même pour les déplacements quotidiens. Cependant,

Dans le choix d’un bon sac à dos, plusieurs facteurs doivent être pris en compte. Quelles que soient ses habitudes, il est essentiel d’avoir un sac à dos qui soit

L’islam est une des plus grandes religions du monde avec plus d’un milliard de fidèles à travers le globe. Cette religion complexe et riche en histoire requiert une compréhension profonde

L’islam est une religion qui repose sur les enseignements du prophète Mahomet, considéré comme le dernier prophète de l’islam. Pour ceux qui souhaitent en savoir plus sur l’islam, il existe

Pour des vacances réussies cet été, envisagez d’aller en bord de mer. Les villes françaises le long de la côte offrent de nombreuses possibilités pour les week-ends ou séjours des

Au cas où vous auriez besoin d’une voiture ou autres équipements, de nombreuses méthodes sont disponibles pour l’effectuer. Vous pouvez procéder à l’achat, à la location ou au leasing qui

Le cinéma français est réputé pour sa qualité artistique, sa sensibilité et son regard sur le monde. Les plateformes de streaming proposent une large sélection de films français, allant des

Vous êtes à la recherche d’une formation qui répondra à vos ambitions professionnelles ? La formation interne est l’outil idéal pour développer vos compétences et booster votre carrière. Entièrement mise

Plongez-vous dans le monde fascinant de la plongée en apnée. Une discipline qui date des temps anciens et a traversé les continents, elle est à présent devenue une forme de
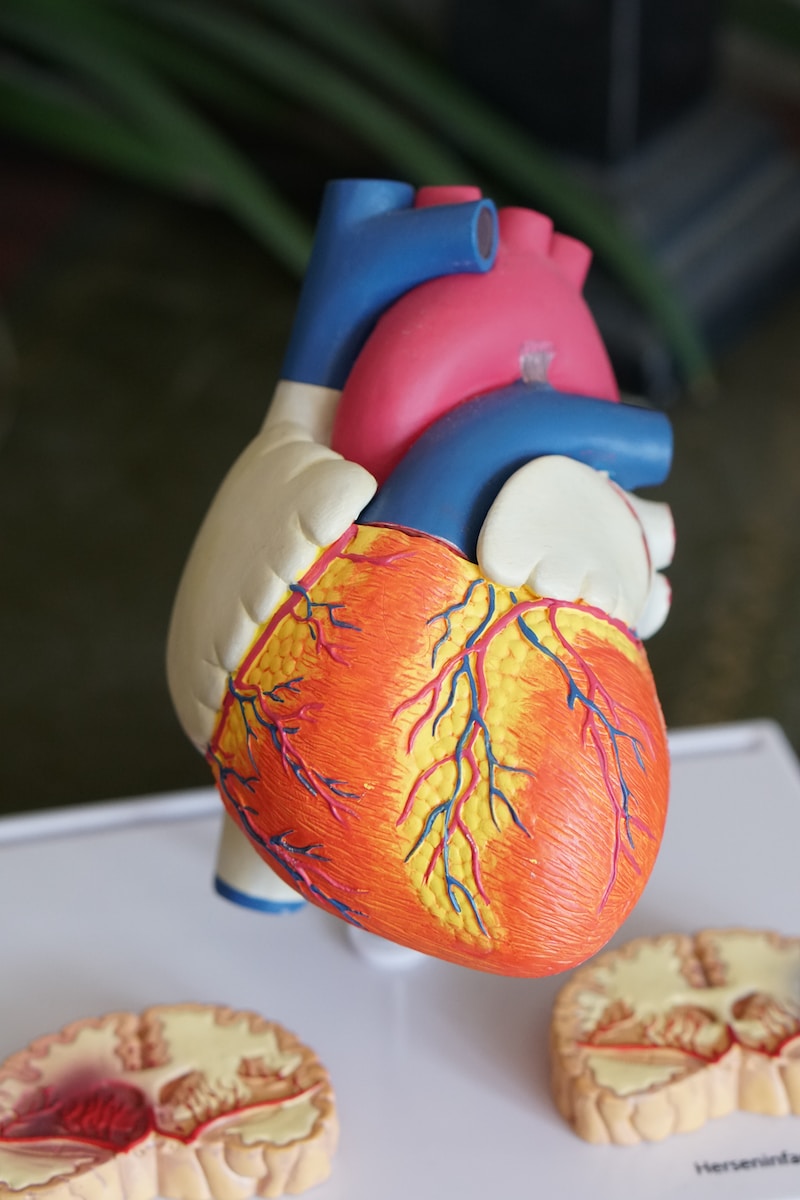
L’insuffisance cardiaque est une maladie sournoise et souvent méconnue qui affecte un grand nombre de personnes. Les causes peuvent être variées, tout comme les symptômes à surveiller, qui sont parfois

Les pompes à chaleur air-eau sont un système de chauffage innovant qui offre une performance thermique exceptionnelle, des économies d’énergie significatives et un confort optimal. Récemment apparues sur le marché,

Les entreprises du Web s’efforcent aujourd’hui de comprendre ce que veulent les utilisateurs et leurs attentes, pour offrir des produits/services plus efficaces et intuitifs. La méthode qui permet cela est

Haïti est une île de légendes, de mystères et d’aventures. Avec ses collines verdoyantes et ses plages immaculées, elle offre aux visiteurs des possibilités infinies pour découvrir sa richesse culturelle

Depuis des siècles, le Karaté a saisi l’imagination de millions d’adeptes à travers le monde. Étudié comme un art martial et une discipline spirituelle, cette pratique consistant à toucher sans

Le Tai Chi est une pratique corporelle ancestrale qui offre de multiples avantages pour tous ceux qui souhaitent retrouver un équilibre et une harmonie entre le corps et l’esprit. La

Vous désirez développer votre force musculaire pour une performance optimale ? La force musculaire est la capacité qu’ont vos muscles de produire des mouvements contre une résistance à un niveau

Les frissons intenses sont une sensation transitoire et involontaire qui peuvent se manifester dans tout le corps. Cette réaction est souvent liée à des sensations de froid, mais peut également

Le référencement naturel séduit de plus en plus les entreprises virtuelles. Aucun site ne peut s’en passer quand il souhaite prospérer. Mais pour maintenir un site web efficace, il faut

Lorsque vous jouez contre un joueur ultra agressif, il est important de pouvoir contrôler la main et le jeu. Avec ces conseils, vous serez en mesure de prendre le contrôle

Un phénomène qui affecte 10 à 15 % de la population française tout au long de l’année est la migraine. La médecine traditionnelle chinoise peut vous aider à soulager votre